# Model-Agnostic Meta-Learning (MAML)
- MAML attempts to answer the question: How to find an initialization for the meta-learner that is not only useful for adapting to various problems, but also can be adapted quickly (in a small number of steps) and efficiently (using only a few examples)?
- 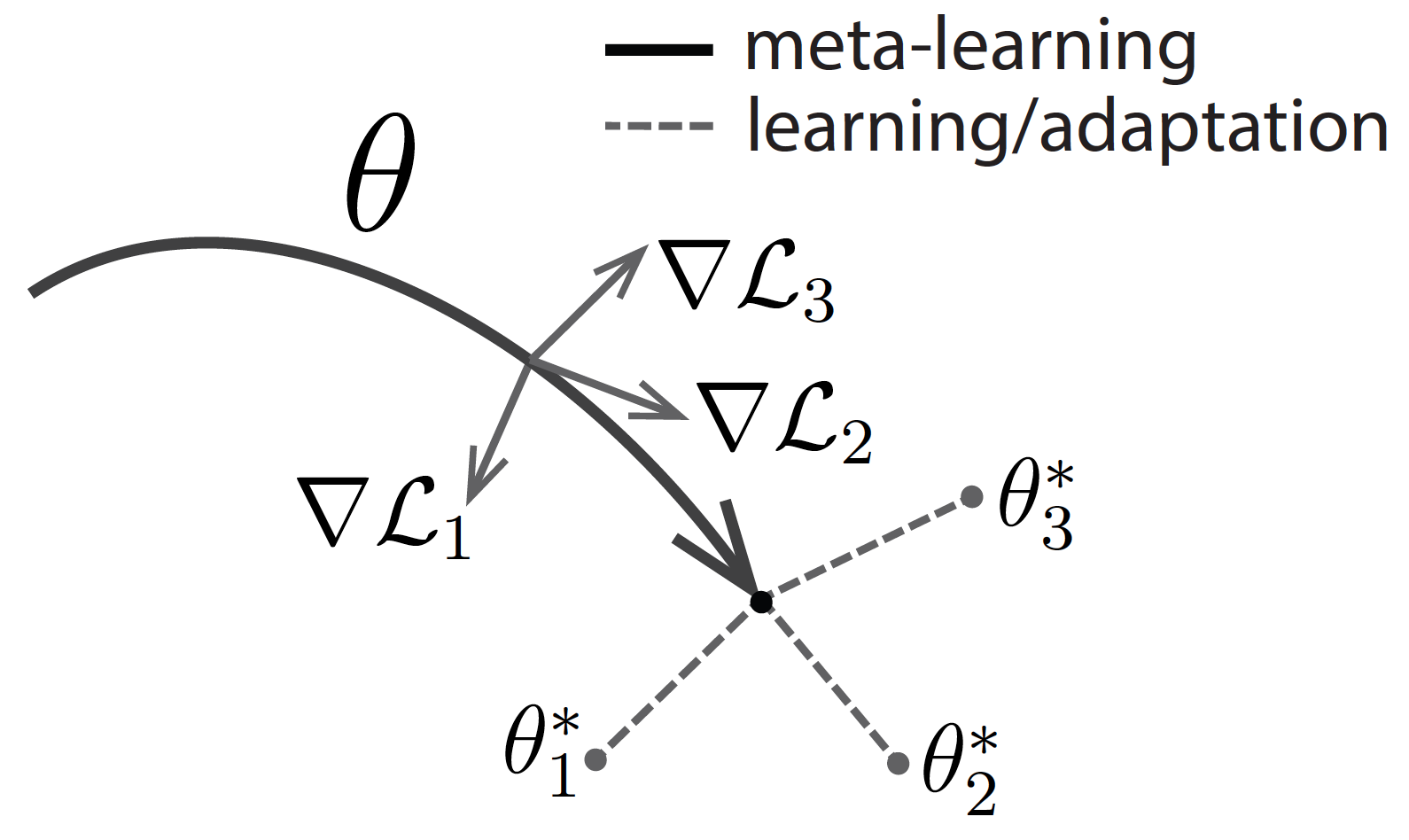
- MAML optimizes for a set of parameters such that when a gradient step is taken with respect to a particular task i, the parameters are close the optimal parameters for task i.
- Doesn't make any assumptions on the form of the model.
- No additional parameters introduced for meta-learning, and uses [[Stochastic Gradient Descent]].
## Advantages of MAML
- Substantially outperform a number of existing approaches on popular few-shot image classification benchmarks, Omniglot and MiniImageNet, including existing approaches that were much more complex or domain specific.
- When MAML combined with [[Policy Gradient]] methods for [[Reinforcement Learning]]. MAML discovered a policy which let a simulated robot adapt its locomotion direction and speed in a single gradient update.
## First-order MAML
- MAML is trained by backpropagating the loss through the within-episode gradient descent procedure. This normally requires computing second-order gradients, which can be expensive to obtain (both in terms of time and memory). For this reason, an approximation is often used whereby gradients of the within-episode descent steps are ignored. This approximation is called first-order MAML.
## ProtoMAML
- Combines the complementary strengths of [[Prototypical Networks]] and MAML.
- By allowing gradients to flow through the Prototypical Network-equivalent linear layer initialization, it significantly helps the optimization of this model and outperforms vanilla fo-MAML by a large margin.
## MAML++
https://arxiv.org/abs/1810.09502
## REPTILE
https://github.com/dragen1860/Reptile-Pytorch
## LEOPARD
https://arxiv.org/pdf/1911.03863.pdf
## iMAML
https://arxiv.org/pdf/1909.04630.pdf
---
## References
1. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.
C. Finn, P. Abbeel, S. Levine. In ICML, 2017. ([pdf](https://arxiv.org/pdf/1703.03400.pdf), [code](https://github.com/cbfinn/maml))
2. Learning to Learn, Chelsea Finnm Jul 2017 https://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/
3. Notes on iMAML https://www.inference.vc/notes-on-imaml-meta-learning-without-differentiating-through/
4. How to train your MAML https://arxiv.org/abs/1810.09502
5. [Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples](https://openreview.net/forum?id=rkgAGAVKPr), Triantafillou et al. ICLR2020
6. MAML high level overview https://www.youtube.com/watch?v=ItPEBdD6VMk